Keresés tartalomra
Kategóriák
Címkék
- Java
- Spring
- Python
- IoC
- Android
- DI
- Dagger
- Thymeleaf
- Markdown
- JDK11
- AOP
- Aspect
- Captcha
- I18n
- JavaSpark
- Microframework
- Testing
- JUnit
- Security
- JWT
- REST
- Database
- JPA
- Gépház
- WebFlux
- ReactiveProgramming
- Microservices
- Continuous Integration
- CircleCI
- Deployment Pipeline
- Docker
- Mocking
- LogProcessing
- PlantUML
- UML
- Modellezés
- OAuth2
- Node.js
- DevOps
- Websocket
- PyPI
- Cucumber
- Next.js
Egyedi query language készítése (nem annyira) egyszerűen és gyorsan
Mindenekelőtt tisztázzuk mi is lenne a cél: egy olyan egyszerű, leíró nyelv definiálása, mely lehetővé teszi egyszerű lekérdezések felépítését, és annak transzformálása a megfelelő feldolgozó logikára. Jelen esetben a már korábban bemutatott TLP (Tiny Log Processor) alkalmazásom számára szerettem volna készíteni egy lekérdezőnyelvet, mellyel a TLP által kezelt logokat tudom a jelenlegi megoldásnál rugalmasabban lekérdezni. A konkrét cél egy SQL-szerű szintaxis elkészítése volt, specifikusan a TLP által ismert és kezelt paraméterek köré felépítve, amivel például a regisztrált alkalmazások neve, a logok szintje, vagy épp a logokban megjelenő error message-ek és stacktrace-ek tartalma alapján tudok kereséseket végezni. Erre egy úgynevezett "környezetfüggetlen nyelv" elkészítése volt a kézenfekvő megoldás - sajnos amennyire ködösek már az emlékeim a korábban említett formális nyelvekről, magamtól biztosan nem lettem volna képes nulláról leimplementálni. Szerencsére nem is kellett, mint kiderült, egészen kiváló cikkeket lehet találni a témáról az interneten - a végül felhasznált cikk linkjét mellékelem a cikkem végén, kiváló olvasmány a téma iránt érdeklődőknek, az alapokat és az implementálási lépéseket is szépen elmagyarázza.
Kezdőlépések
Az első és legfontosabb lépés a nyelv megtervezése. Nyilván ha semmilyen koncepciónk nincs fejben, jobb ha hozzá se kezdünk, mert a nyelv feldolgozó megírása pont nem olyan dolog, amit "majd kitalálunk útközben" - megpróbálni meg lehet persze, de akkor nagyjából fél óránként refaktorálhatjuk majd az egész addig elkészült kódunkat. Mint azt a bevezetőben említettem, az én koncepcióm egy SQL-szerű nyelv volt (végül legfeljebb felépítésében lett SQL-szerű, de ez más kérdés), mellyel feltételeket tudok meghatározni a tárolt logokra, valamint rendezni tudom azokat, illetve a "lapozást" is elengedhetetlen funkciónak gondoltam. Így született meg az alábbi terv, egy olyan elképzelt query formájában, ami amolyan demoként a szolgált a nyelv képességeit illetően:
search
with conditions
source = "lflt" // filter to source, thread, logger, level, etc....
and level either ("info", "error") // match for any of the values in the list
and level none ("warn", "debug", "trace") // match for none of the values in the list
and ( // grouping
message = "..." // exact match
or message ~ "..." // approximate match
)
and message != "..." // negated match
and timestamp > 2019-01-01
or timestamp between [2019-01-01 00:00:00, 2020-01-01 00:00:00] // inclusive search, exclusive with ] ... [, inclusive from left, exclusive by right [ ... [
with order by
timestamp desc
then level asc
with limit 10
with offset 100
A lekérdezések tehát a search kulcsszóval kezdődnek, majd a with conditions (feltételek), with order by (sorrendezés), with limit (visszatérő bejegyzések maximális száma), illetve a with offset (eltolás) szekciókkal folytatódhat. Ezek sorrendje egyébként tetszőleges lehet, de mindig a search kulcsszó kell nyissa a lekérdezést. Nyelvi készlet terén vannak
- objektum referenciáink (source - alkalmazás, amely a logot beküldte; level - log szint; message - log tartalom; timestamp - log időpontja; logger - logger név;
- kulcsszavaink (search, with, conditions, order, by, then, asc, ascending, desc, descending, limit, offset);
- operátoraink (=, !=, ~, <, >, <=, >=, either, none, between, and, or);
- szimbólumaink (szögletes és "sima" zárójelek, vessző);
- illetve literáljaink (string, szám, dátum, dátum és idő).
Mindezt azért volt fontos felsorolni, mert ezek a nyelvünk tokeneknek nevezett építőelemei, és ezekkel kell majd dolgoznunk a továbbiakban. Ezek a tokenek egymást meghatározott szabályok szerint kell kövessék, hogy azok értelmes "mondatokat" alkossanak, a szabályok összességét pedig nyelvtannak hívjuk, pont mint egy természetes nyelvben. És itt kanyarodunk rá a korábban említett környezet vagy kontextus független nyelvekre, mint amilyen ez a nyelv is. Kontextus függetlennek nevezzük a nyelvtant akkor, ha az pusztán a szintaxisa alapján feldolgozható, tehát a nyelv nem tartalmaz például változókat, melyeknek az értékét is figyelembe kell venni a feldolgozás során. A szabályok fogják meghatározni, melyik tokenből melyik tokenbe mehet át a feldolgozó, és ha ettől eltérő átmenetet talál, az szintaxis hiba. (A nyelvi készlet egyébként itt megtekinthető)
A szabályoknak van egy kiváló tulajdonsága: nagyon egyszerűen, szinte motorikusan absztrahálhatóak, egy szabály implementálása sok esetben "gyerekjáték" - némi túlzással persze. Viszont éppen ezért érdemes úgy nekiállni a fejlesztésnek, hogy előtte már megvannak a szabályok, azokat már felskicceltük magunknak és pontosan tudjuk a nyelvnek milyen token átmenetei lehetnek. Sajnos az erősen hiányos formális nyelv ismereteim miatt nekem ez nem ment zökkenőmentesen, azt hiszem a mai napig pontatlan a nyelvi definíció, de szerencsére annyiból ez már nem is számít, hogy a feldolgozó már implementálva van és szerencsére hibátlanul működik is. Példaképp azért álljon alább néhány ilyen szabály, magyarázattal:
SEARCH -> search WITH: belépési pontunk aSEARCHnevű szabály, asearchkulcsszót követően aWITHszabályra lép át;WITH -> with CONDITIONS: aWITHszabályból 4 verzió is létezik, az egyik lehetőség awithkulccsszót követően aCONDITIONSszabály ...WITH -> with ORDER_BY: vagy azORDER BYszabály ...WITH -> with LIMIT: vagy aLIMITszabály ...WITH -> with OFFSET: vagy azOFFSETszabály.CONDITIONS -> conditions TIMESTAMP_CONDITION: aCONDITIONSszabály is 3 módon mehet tovább, az egyik lehetőség, hogy aconditionskulcsszót követően egyTIMESTAMP CONDITIONszekciót azonosítunk...CONDITIONS -> conditions MULTI_MATCH_CONDITION: vagy egyMULTI_MATCH_CONDITIONszekciót...CONDITIONS -> conditions SIMPLE_CONDITION: vagy egySIMPLE CONDITIONszekciót.
És így tovább, ez még a nyelv szabályainak alig néhány százaléka volt - akit érdekelnek a további szabályok, a cikk végén mellékelem a feldolgozó repository linkjét, ott a hu.psprog.leaflet.tlql.grammar.strategy.impl package-ben található osztályok Javadoc-jában megtalálhatóak a továbbiak.
Feldolgozó lépések
A feldolgozás természetesen több lépésből fog állni, minden lépés során más-más aspektusból fogjuk vizsgálni a megadott query szöveget. A teljes folyamat nagyjából így fog kinézni (a továbbiakban ezt fogjuk részleteiben megnézni):
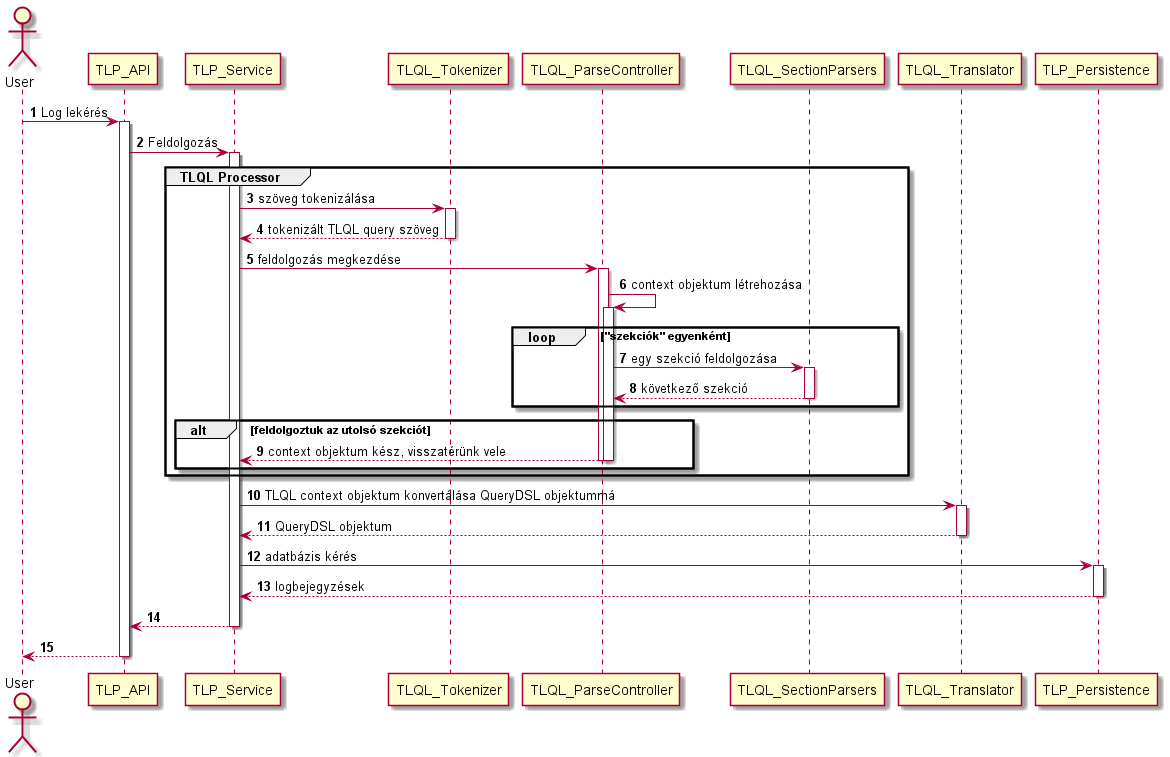
Most elsősorban a TLQL Processor dobozban látható komponensekre illetve a TLQL_Translator komponensre fókuszálunk majd, mivel a TLP működését már egy korábbi cikkemben bemutattam.
TLQL tokenizálás
A feldolgozás első lépése a query szövegének tokenizálása, mely során a szöveget "szavakra" tördeljük. A nyelv szavai a korábban már bemutatott nyelvi készletből fognak származni - ettől bárminemű eltérés szintaxis hibát eredményez, tehát már a tokenizálás sikertelen lesz. A tokenizálás eredménye egy egyszerű láncolt lista, melyben az egymást követő szavak találhatóak. Explicit nyelvi kulcsszavak esetén maguk ezek a szavak lesznek reprezentálva, literálok esetén a literál típusa és annak (szöveges) értéke lesz megtalálható a listában. Vegyük példának a következő query-t:
search with conditions source = "leaflet"
A tokenizáló a következő listát építi majd:
KEYWORD_SEARCH
KEYWORD_WITH
KEYWORD_CONDITIONS
OBJECT_SOURCE
OPERATOR_EQUAL
LITERAL_STRING_QUOTE("leaflet")
A feldolgozás során a parser ezen a listán megy majd végig, ellenőrizve, hogy a szabályoknak megfelelő-e a szavak sorrendje, tehát szintaktikailag helyes-e a query. A tokenizálás egyébként egy viszonylag egyszerű módszerrel működik, mégpedig reguláris kifejezésekkel tördeli a szöveget. Ténylegesen arról van szó, hogy megkeresi a szövegben léteznek-e adott szavak és ha igen, azok hol kezdődnek. Ez utóbbi nagyon fontos információ, mert ez alapján tudja sorba rendezni a szavakat a tokenizáló. Továbbá amiatt is fontos a szavak kezdőpozíciója, hogy ha esetleg két token is felismerhető egy szövegrészletben az adott pozíción, akkor eldönthető, melyikkel van valójában dolgunk ezen a ponton. Ilyen például a dátum és a dátum+idő literál közti különbség. A dátum literált leíró reguláris kifejezés fel fogja ismerni a dátum+idő literálokat is. Ez esetben azonban látható lesz, hogy ugyanazon a pozíción van egy dátum és egy dátum+idő literál is, ami persze nem lehetséges, tehát ez esetben priorizáljuk a dátum+idő literált és azt fogadjuk el igaznak, a dátum literált pedig eldobjuk.
Parse-olás
A tokenizálás után kezdődhet a query tényleges feldolgozása. Ezen a ponton még csak azt tudjuk, hogy van egy szövegünk, ami a nyelvkészlet elemeit tartalmazza, szintaktikai és szemantikai helyessége azonban még ismeretlen - ekkor jön képbe a parser. A parser a TLQL feldolgozójában egy stratégia vezérlő implementáció, mely első lépésként létrehoz egy context objektumot - ebben fogjuk tárolni a queryből kiolvasott információkat. Maradva a fenti példánál, egy ilyen kiolvasandó információ lesz egy feltétel, mely a "leaflet" alkalmazás által leírt logokra szűkíti a keresést. A parser a context objektum létrehozása után a "search" szekció feldolgozására utasítja a vezérlőt, mivel ez az első, kötelezően elvárt kulcsszó. A feldolgozás ekkor átkerül a search szekció stratégia implementációhoz. (Ebben a példában egyébként 4 különböző szekciónk lesz, a 3 keyword és az objektum-operátor-literál komponensekből álló feltétel.) Ezek az implementációk minden esetben az alábbi műveletek tartalmazzák:
- Meg tudják mondani, ők melyik szekció feldolgozására alkalmasak, tehát a belépési pontjukat.
- Meg tudják mondani, melyik szekcióra képesek átléptetni a vezérlést, tehát a kilépési pontjukat. Ez az információ lesz felhasználva arra, hogy a parser a következő szekció feldolgozóra tudjon lépni, ha még van hátra.
- És végül el tudják végezni az információ kinyerését és a kontextus léptetését.
A folyamat tehát úgy néz ki, hogy a parser a search szekció feldolgozására utasítja a vezérlőt, ami kiválasztja a search szekció parsert a forSection() metódus válasza alapján. Ez utóbbi megnézi, hogy valóban a search kulcsszó olvasható-e az aktuális ponton és ha igen, eldobja azt, léptetve a kontextust a következő kulcsszóra, ami a with lesz. Ezután jön a lényegi része a feldolgozásnak, az információ kiolvasása és a kontextus léptetése - a search szekció esetében ez csupán a léptetést jelenti majd. Ezután a szekció parser visszatér, a chainTo() metódus válasza pedig arra fogja utasítani a parsert, hogy a kontextust a with kulcsszó feldolgozására léptesse. A parser betölti a megfelelő szekció parsert és a folyamat egészen addig megy tovább hasonló lépésekkel, míg a szöveg végére nem érünk, vagy egy szintaxis hibára nem bukkanunk.
A with kulcsszónál azonban rögtön van egy érdekesség, az ugyanis nem csak egy irányba képes továbbléptetni a feldolgozót. A with szekciónak szüksége lesz a kontextus következő szavára is, ami az úgynevezett "look-ahead"-ek bevezetését igényli. Erről még nem volt szó, de működésük elég egyszerű: egy look-ahead mindig a következő szóra mutat a szövegben. Tehát van egy éppen aktuálisan feldolgozott szavunk, és van egy look-ahead, ami az utána következő szó lesz. Ez esetben például with (aktuálisan feldolgozott szó) és conditions (look-ahead). Mivel így mindig a következő 2 szóval foglalkozunk gyakorlatilag, ez a nyelv egy úgynevezett LL(2) nyelvtan. (Ez csak amolyan érdekesség volt a formális nyelvek témaköréből.)
A fenti példánál maradva egyébként egy "simple condition" szekcióhoz fogunk érkezni, aminek a feldolgozó lépése ki fogja olvasni az objektumot, operátort, és értéket, amiket formalizál majd elhelyez a context objektumban. A context objektumhoz hozzáadott feltétel az lesz, hogy a source objektum (logot létrehozó alkalmazás) értéke legyen egyenlő azzal, hogy "leaflet". A szavak ezután elfogynak a kontextusból és a parser kilép. Természetesen a feldolgozás nem mindig ennyire egyszerű, a mellékelt repositoryban megtekinthető az összes szekció parser implementációja - némelyiket kifejezetten bonyolult volt összerakni, főleg a "különlegesebb" esetek miatt.
Fordító
Gyakorlatilag a nyelv feldolgozása ezen a ponton már kész van (kivéve ha szintaxis hibába futottunk), de igazából még teljesen haszontalan az egész. A feldolgozás eredményeképp már van egy context objektumunk, amiben megtalálhatóak a felismert feltételek, sorrendezési beállítások, és a lapozás beállításai. Ebből azonban így még nem lesznek logjaink, mivel nagyjából most járunk ott, hogy meghívtunk egy API-t bizonyos értékekkel, amikből még adatbázis kérést kell generálni.
Ez a lépés azonban már független a TLQL feldolgozójától, ennek oka pedig nagyon egyszerű. Amikor megírunk egy ilyen nyelvet, nem feltétlenül szeretnénk, ha az csak egy adott rendszerrel (például egy specifikus adatbázis motorral) lenne képes együttműködni. Ennek megoldása az, hogy a context objektum "fordítását" az integráló félre bízzuk, ez esetben a TLP-re. Mivel korábban már használtam a QueryDSL nevű library-t a logok MongoDB-ből való lekérdezésére, így maradtam ennél a megoldásnál, persze a v1-es API által biztosított paraméterezés messze elmaradt komplexitásban a TLQL context objektumától, így azt újra kellett írnom. Az átalakítások megtekinthetőek a TLP hu.psprog.leaflet.tlp.core.service.qdsl.expression package-ében
Konklúzió
Nagyjából ezek lennének a lényeges pontjai egy query language elkészítésének. Természetesen nem feltétlenül lesz szükségünk egy ilyen elkészítésére, azonban nem is lehetetlen megoldani, ha arra van szükség, és igazából egy elég izgalmas feladat összességében. Azt is érdemes kiemelni, hogy a TLQL csak egy példa volt, sok másféle esetben is belefuthatunk egy egyedi lekérőnyelv megírásának igényébe. Azonban mielőtt belevágunk, azt tudom javasolni, hogy mindenképp végezzünk alapos felmérést, vajon tényleg szükség van-e rá, hiszen nem feltétlenül egyszerű és gyorsan elvégezhető feladatról beszélünk, bár ez teljesen komplexitás-függő. Ha a leendő nyelvünk csak egyszerű, egymáshoz hasonló lépések elvégzésére képes, a nyelvi készlet összeállítása, a tokenizáló és a parser implementálása nem vészes feladat, a lépés feldolgozó pedig valószínűleg jól általánosítható lesz. A formális nyelvek elméleti alapjainak ismerete sem elengedhetetlen előfeltétel szerintem, bár kétségkívül kívül hasznos, ha tisztában vagyunk vele, egészen pontosan mit csinálunk.
Felhasznált tartalom:
How to Create a Query Language DSL with C# - Jack Vanlightly
Linkek
Tiny Log Query Language (TLQL) nyelv feldolgozó
TLP átalakítások a TLQL támogatás bevezetésére
Komment írásához jelentkezz be
Bejelentkezés
Még senki nem szólt hozzá ehhez a bejegyzéshez.